Building a simple AI-driven research tool that works from anywhere on any computer

When using large language models like ChatGPT or Perplexity or Phind in my day to day routine - I find myself working with two workflows.
The first is the one that they excel at - conversational interfaces to explore a topic in-depth and exhaustively ask questions until I get the information I need.
The second is more of a replacement for Google. I find myself using Google to get answers to simple questions, but more recently I ask a large language model instead, since Google often involves an additional click into Wikipedia and so on. The Google Assistant is optimal for this on the phone, with Google Lens and other tools baked into Android.
Having efficient access to this workflow is useful because you can stay focused on the task at hand without switching context.
So I recently set myself a challenge. In the current “Golden Age of AI”, can I build a proof of concept that amplifies AI-driven productivity for everyone? The goal would be to create something that’s close to Siri, but powered by a Large Language Model, and available across platforms, to everyone, even on a low-budget computer.
The Problem
If you’re a non-technical person without the means to afford a subscription to a large language model product or tool, you are deprived of a bunch of productivity. Your operating system also doesn’t offer a great assistant solution. Siri comes close to what we want, but we can attempt something better as a proof-of-concept.
The average person in this situation is young, maybe a student or fresh graduate, maybe reading research papers, Wikipedia, writing with Google Docs or Microsoft Word. Perhaps they’re writing some code, or using Microsoft Excel, or just browsing websites or watching a YouTube video.
Often in this scenario you run into something that you need help with, and you alt-tab to Google or Perplexity or ChatGPT or Bing or Poe and type out your query. For non-technical folks or those typing at less than 80wpm, or both, this already creates some friction because you have to expend so much time and effort to just to clarify something.
This type of friction often means that people just won’t do it. This results in poorer understanding, learning outcomes, adoption of AI, etc.
Existing Solutions
Microsoft is already working on this for the next generation of laptops. In January 2024, they confirmed the addition of a “Copilot Key” on future generations of laptops. This will enable users to invoke their Copilot tool from any application, and either speak to it, or type their queries. This is the kind of productivity leverage that would solve the problem, but it’s not widely available today.
There are a host of indie developers that have already built this type of products. Let’s review what’s on offer.

Apps like AI Anywhere offer ~10 queries per day for free, where you can have an excellent workflow and intuitive UI to solve the aforementioned probem. For ~$10/mo and ~$15/mo you can graduate to higher tiers with higher limits. This feels wasteful because there are better options out there.
There’s Chatbox which is great and ticks many of these boxes including the keyboard shortcut. Great UI, conversation history, scales with the user (in the sense that if you have better hardware, you can use local language models, or if you have disposable income, you can configure your API keys and pay a tiny amount per query). This was released a little over a year ago, and is now a mature project with over 50 releases and improvements since. It’s similar to Anthropic’s Poe, but runs on your machine and works off your API keys. I’d recommend this to most people looking for a solution like this.
There’s a list of similar apps maintained at the Awesome ChatGPT GitHub repository, of which ChatBox seems to be the most feature-rich and cross-platform.
These solutions are great, but in terms of efficiency and productivity they don’t quite address the point I made earlier.
I’m omitting open source language models on purpose as part of the overall context, because an entry-level laptop is not going to be able to run anything worthwhile, even if it’s a 7B or 3B quantized model, the tradeoff isn’t very good compared to other solutions as of today.
Building a “poor man’s smart Siri”
Going back to the workflows described earlier:
When using large language models like ChatGPT or Perplexity or Phind in my day to day routine - I find myself working with two workflows.
The second is more of a replacement for Google. I find myself using Google to get answers to simple questions or more recently I ask a Large Language Model, instead.
So, what does this look like?
- I ask a question, get a response (Voice).
- I highlight some text, press a hotkey, ask a question, get a response (Voice).
- The same thing, except with a text response. I might use this variation if I want to be able to copy and paste the result. Useful if I want a summary or outline.
Here are two demos:
Voice -> Voice
The Gemini Pro Free API can be slow at times, performance often varies, I included this video to share a sense of a worst-case performance scenario
Voice -> Text
Typical performance. This is more representative of the value I’ve derived from the tool. It goes without saying that accuracy with regard to speech recognition and Gemini itself are a source of annoyance in a minority of cases.
You may also notice that I am using a very cheap and poor quality standby microphone. This is temporary until I get my new headset, after which this system will start to perform a lot better in terms of latency and accuracy.
Architecture
The program is simple, cross-platform and requires some degree of configuration to set-up.
The overall architecture is as follows:
-
LLM: Gemini Pro API (Free, they use your data to train, 60req/min limit). This is one of the worst models available today in terms of performance, but useful enough for this use-case. More on this later.
-
Speech Recognition: For this use-case OpenAI’s Whisper “base” model is good enough to understand perhaps 80% of the voice prompts. Depending on your hardware resources, this can be scaled up to small, medium, large, etc. with a performance tradeoff on latency. Since the goal of this project was to find a solution that would work for almost anyone, the base model does the job fine, and uses about 150MB of RAM, which is not much. To ensure we can run efficiently without a GPU, we run the whisper.cpp project that helps us run on a CPU, which opens up this feature even if you don’t have a GPU, which is the vast majority of people.
-
TTS: For text-to-speech, there are a bunch of cloud options ranging from ElevenLabs which is among the best and most expensive, to Neets which has reasonable quality and latency, and a reasonable free-tier (25k characters per month), along with the usual players - OpenAI and Google. For us, the condition is that it must be free, so we’re using Piper which runs locally and has reasonable voice quality. If we drop the quality of voice further, we could use a barebones espeak or
sayon macOS. -
VAD: For quality of life, we want to detect when the user is done speaking, so we use a Voice Activity Detector. Python’s webrtcvad is old but does the trick. One could also use Silero for better performance, but from my testing it looks it would consume more resources, and depends on PyTorch.
Putting it all together
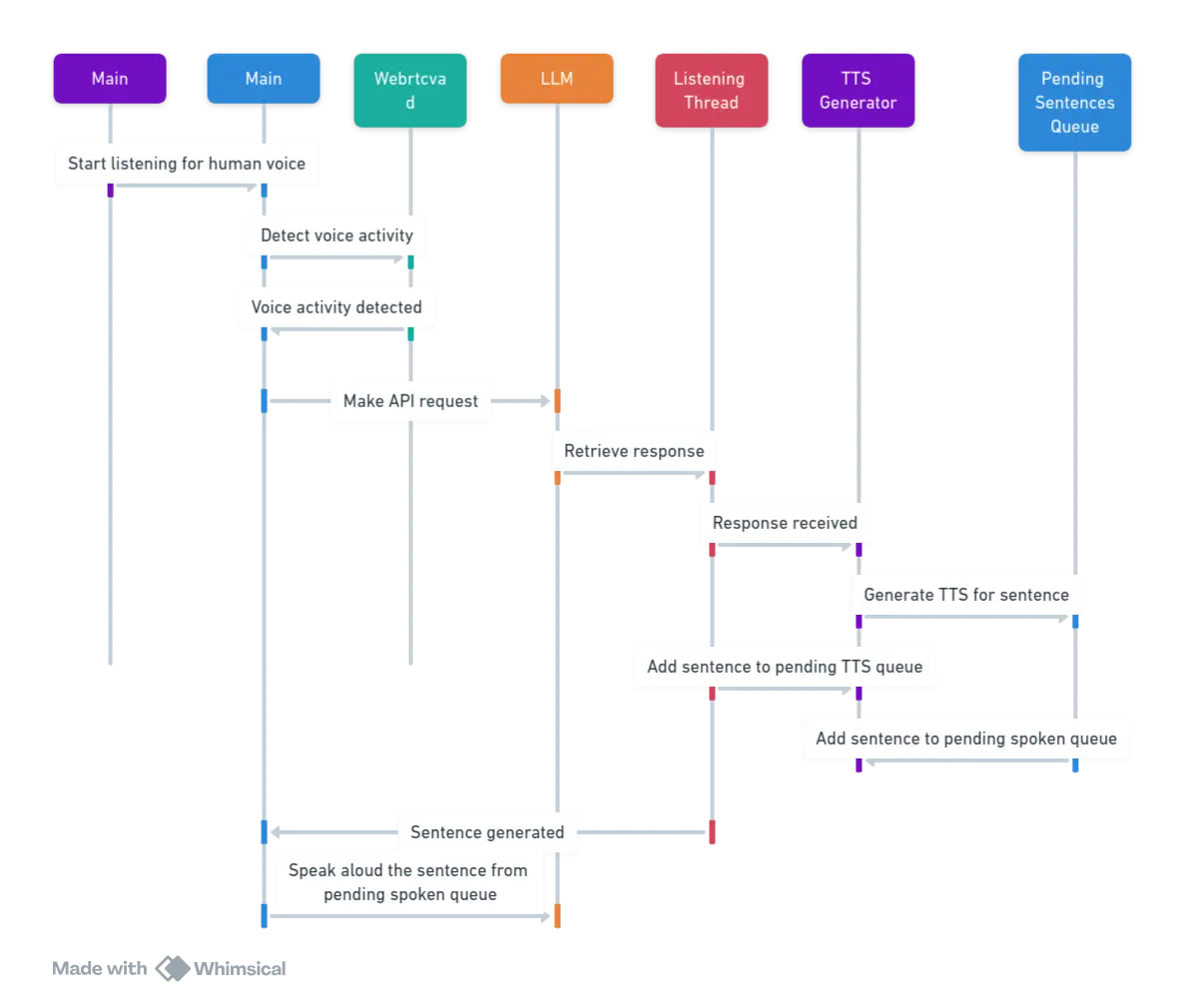 This diagram was AI generated based on an elaborate explanation. It does a pretty good job nonetheless.
This diagram was AI generated based on an elaborate explanation. It does a pretty good job nonetheless.
A rudimentary ~300 line Python script can put this all together. What’s not covered is the configuration of a system-wide hotkey to trigger the script, since it differs from operating system to operating system. Nonetheless, most operating systems have convenient ways to set-up system-wide hotkeys that can run a script that are more-or-less simple to set-up.
The program runs in the background on a socket as a process. The 4 hotkeys execute another triggering script that sends a message on the socket that activates one of the 4 types of interfaces, depending on the hotkey:
- In: Voice, Out: Voice
- In: Voice, Out: Text (Popup Window)
- In: Voice + Text Selection, Out: Voice
- In: Voice + Text Selection, Out: Text (Popup Window)
For the GUI window, Python comes with Tkinter out-of-the box, which can spawn windows across operating systems.
What’s Next?
I hope that OS vendors embrace this type of workflow and offer something like it as a core feature of the operating system. Microsoft has already started this with CoPilot on Windows 11 which is slowly rolling out to all users. I expect the next iteration of Siri to include a lot of these productivity features, and more. Once it becomes mainstream, it won’t be long before several clones follow.
The primary challenge behind turning something like this into a usable product lies in the diversity of user configurations that can lead to troubleshooting issues. These range from handling multiple audio input and output sources, handling bluetooth and disconnections / handover to other devices, and a whole lot of other such edge-cases. The core of the application in the proof-of-concept would, in all likelihood, end up being the smallest effort of the whole exercise. There are great open-source projects like ChatBox already out there. It may make more sense to refine them to a similar workflow and enable users to resolve these configuration related requirements via menus.
I may do a follow-up blog post if I create another iteration of the project, or a packaged release.
Writing the Code
For all the praise that is heaped on contemporary large language models, we are still not in a place where I could spell out my requirements for an application like this to the language model and have it write most of the code without a whole range of mistakes.
A better approach is to break the problem up into the aforementioned architecture and tackle each part of the problem separately. In such cases, handing off the task to a language model like GPT4 yields better results.
Another place where language models shine in this regard is when developers need assistance in comparing open-source package offerings. I was able to evaluate Qt5 and Tk as potential candidates for the popup window feature, however the model was still not smart enough to anticipate that Qt5 comes with more specific requirements regarding threading and interacting with the window from a background process. This would be a core requirement here, since the language model sends back the result in chunks.
The Code
The following code is a very rough proof of concept with a few quality of life issues that are easily fixed, but does the job quite well and solves the productivity problem in a simple way until better options come along.
A well-written version would have a modular / object-oriented design with abstractions written to handle all of the core functionality. This would enable users / developers to swap out language models, TTS and speech detection easily, and for future updates to take care of specific functionality by just changing implementation details. Since this project has only 1 user for now, all of that is unnecessary at this point in time.